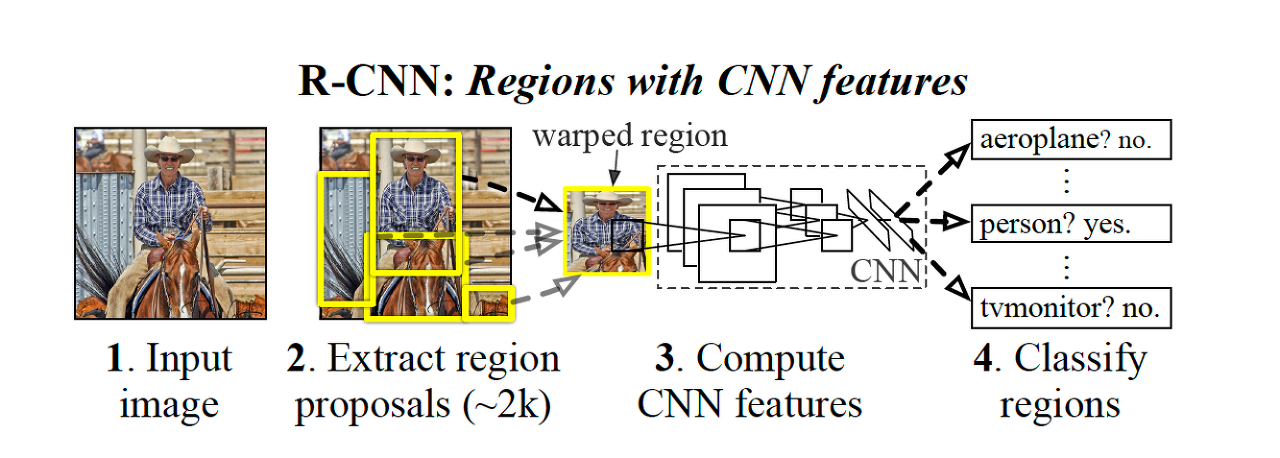
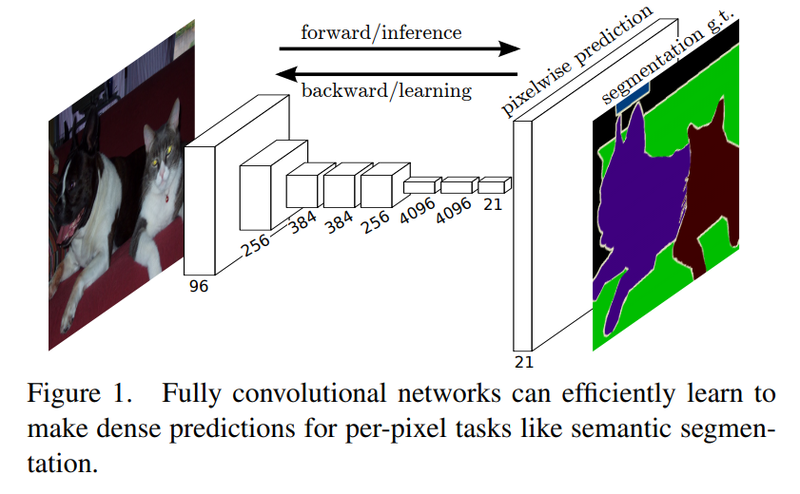
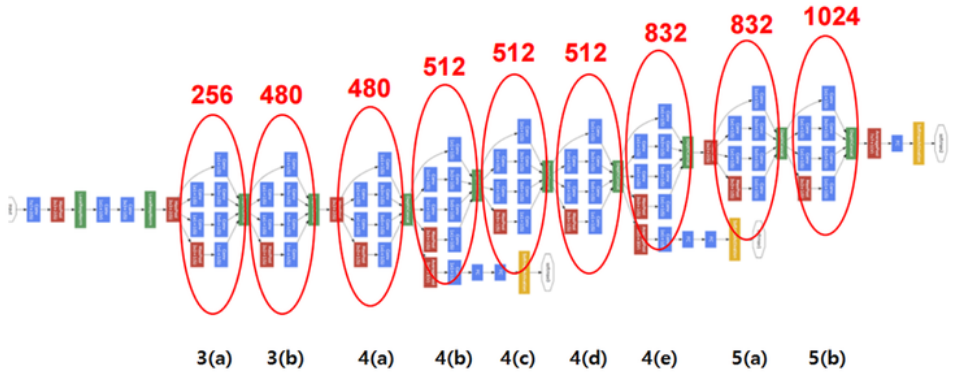
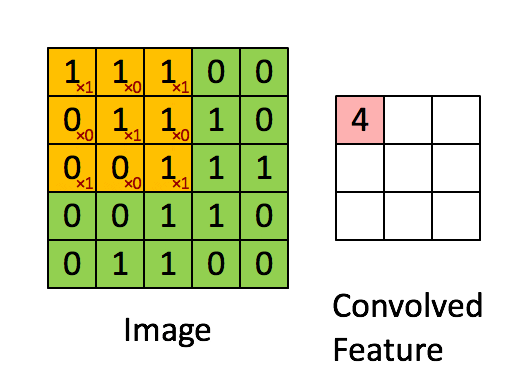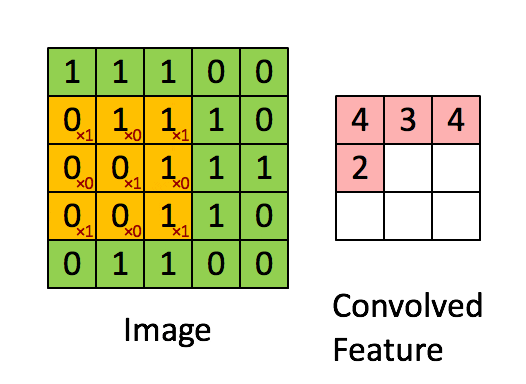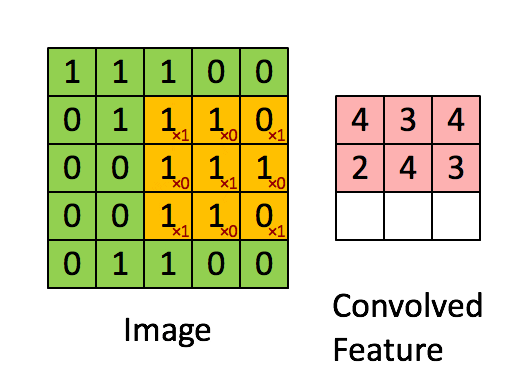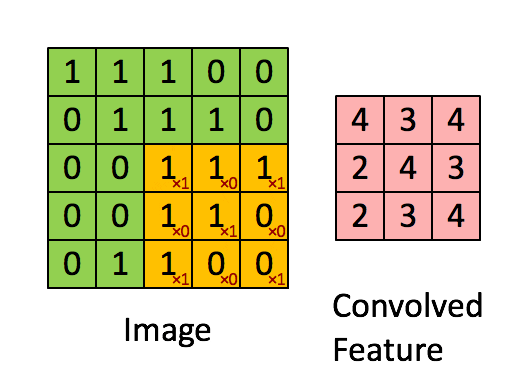
[CV basic] Data Efficient Learning
Data augmentation 데이터셋은 대부분 편향되어있다. 훈련 데이터와 실제 데이터 사이에는 항상 차이가 있기 때문에 data augmentation을 통해 실제 세상에 있는 데이터와의 차이를 매꿔야 한다. 데이터 증강을 하는 방법으로는 데이터를 회전시키거나 좌우반전시키는 Flip/Rotate, 색을 변경하는 방법, 임시로 이미지의 크기를 자르는 Crop, Affine 변환, 각기 다른 이미지를 잘라서 붙이는 Cutmix, 노이즈를 주어 흐리게 만드는 blur 등의 여러 기법이 있다. PyTorch의 코드에서는 albumentations, transforms등의 함수를 사용해 data augmentation을 간단히 진행할 수 있다. albumentations_transform = albument..