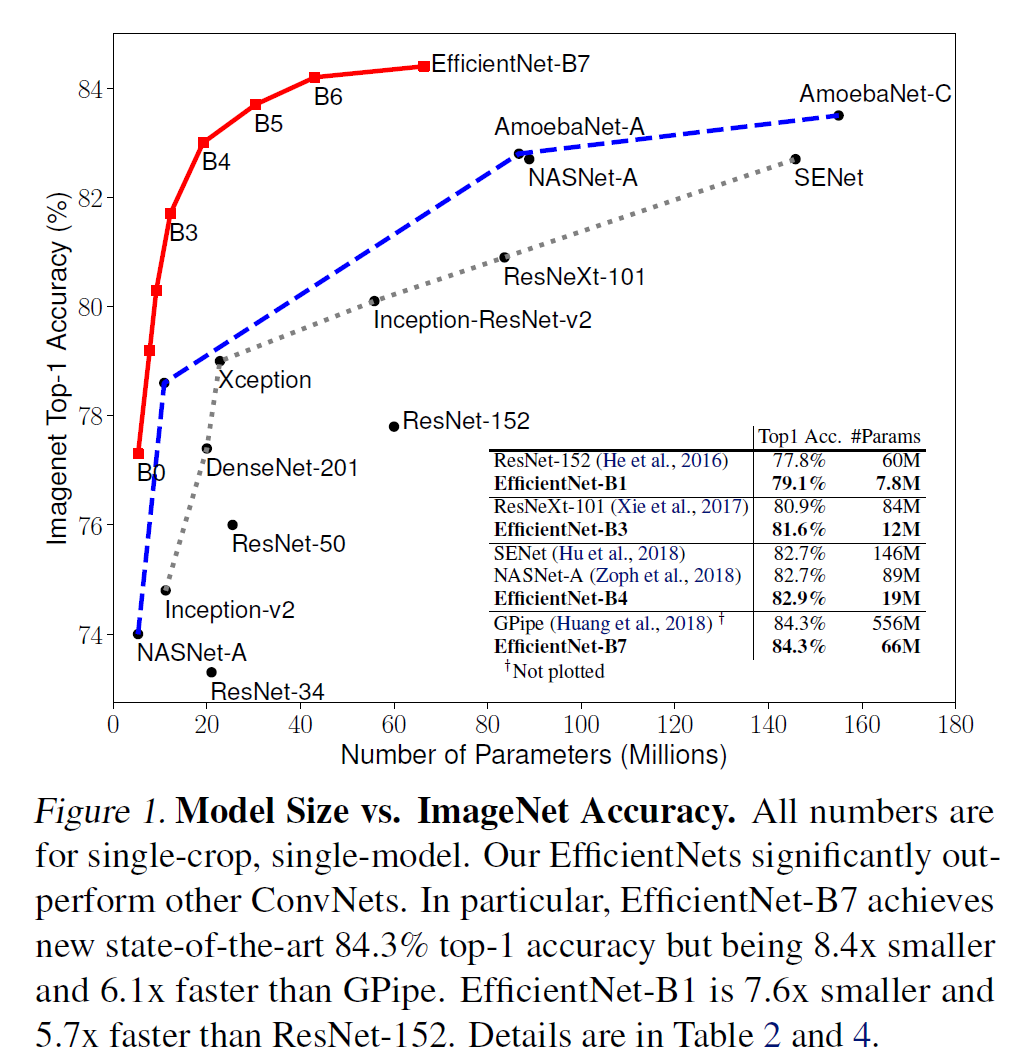
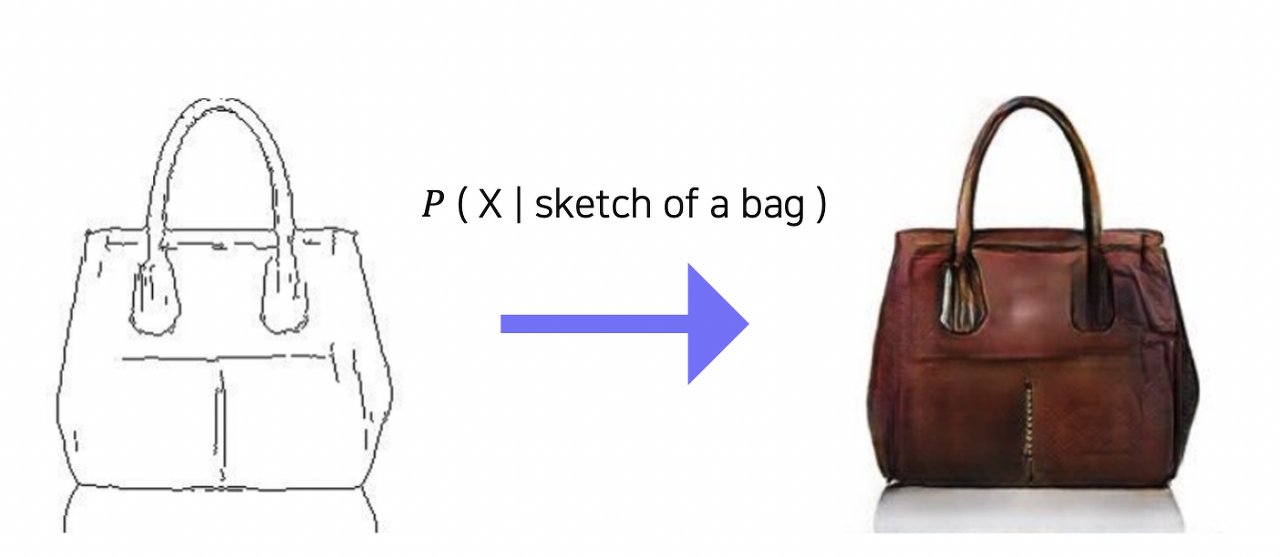
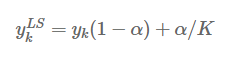Transformer를 사용한 모델도 사용해보자는 의견이 있어 정리하고 사용해보기 위한 정리글. ViT (Vision Transformer) NLP 분야에서 한 획을 그은 (GPT 모델에도 사용되는) Transformer를 image classification 분야에 맞게 변형하며 CNN을 사용하지 않도록 만든 모델. 사실상 이 모델의 등장 이후 CNN을 사용한 모델의 종말을 예고했고, Transformer가 NLP뿐 아닌 CV까지 뻗치며 인공지능의 근본이 되었다. 1. 이미지를 여러 개의 patch로 자른 후 각 패치별 embedding demension (16 x 16 x 3)으로 만든다. 이를 통해 기존 Transformer 모델에서의 시퀀스 데이터와 같이 만든다. 2. 각 패치에 대한 flatte..