https://www.youtube.com/watch?v=o8RkbHv2_a0
NewJeans Attention Is All You Need
Sequential Model
seq2seq 모델의 경우 인코더-디코더 구조로 구성되어 있다. 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해 출력 시퀀스를 만들어 낸다. 하지만 이 과정은 입력 시퀀스가 벡터로 압축되는 과정에서 그 정보가 손실되고, 이럴 보정하기 위해 사용하는 기법이 어텐션이다. 트랜스포머는 이 어텐션만으로 인코더와 디코더를 만든다는 아이디어에서 고안된 모델이다. 그래서 Attention Is All You Need라는 논문으로 게재되었다.
High-Level Look for Transformer

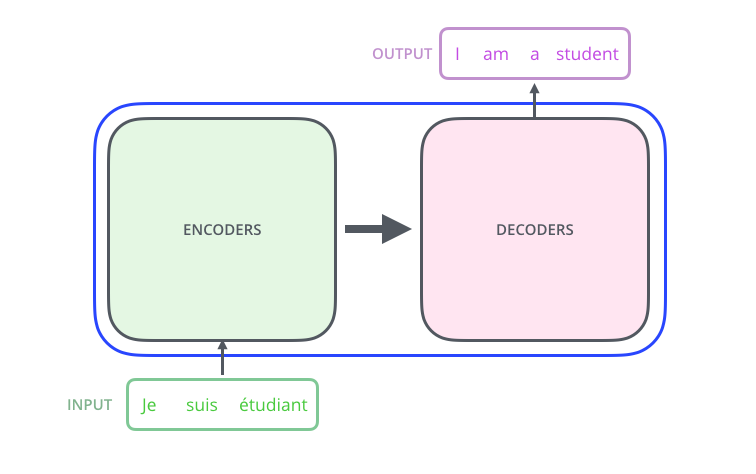

인코딩 구간의 구조는 여러 개의 인코더를 stack형식으로 쌓아 놓은 구조이다. 또한 디코딩 구간 역시 여러개의 디코더를 쌓은 구조이다.
여섯 개의 서로 정보가 공유되지 않는 인코더와 디코더로 구성된 모델에서 각각 어떤 정보들이 인코더에서 디코더로 넘어가는걸까?

인코더 내에 들어간 Self-Attention이 바로 트랜스포머 모델의 정체성이다.
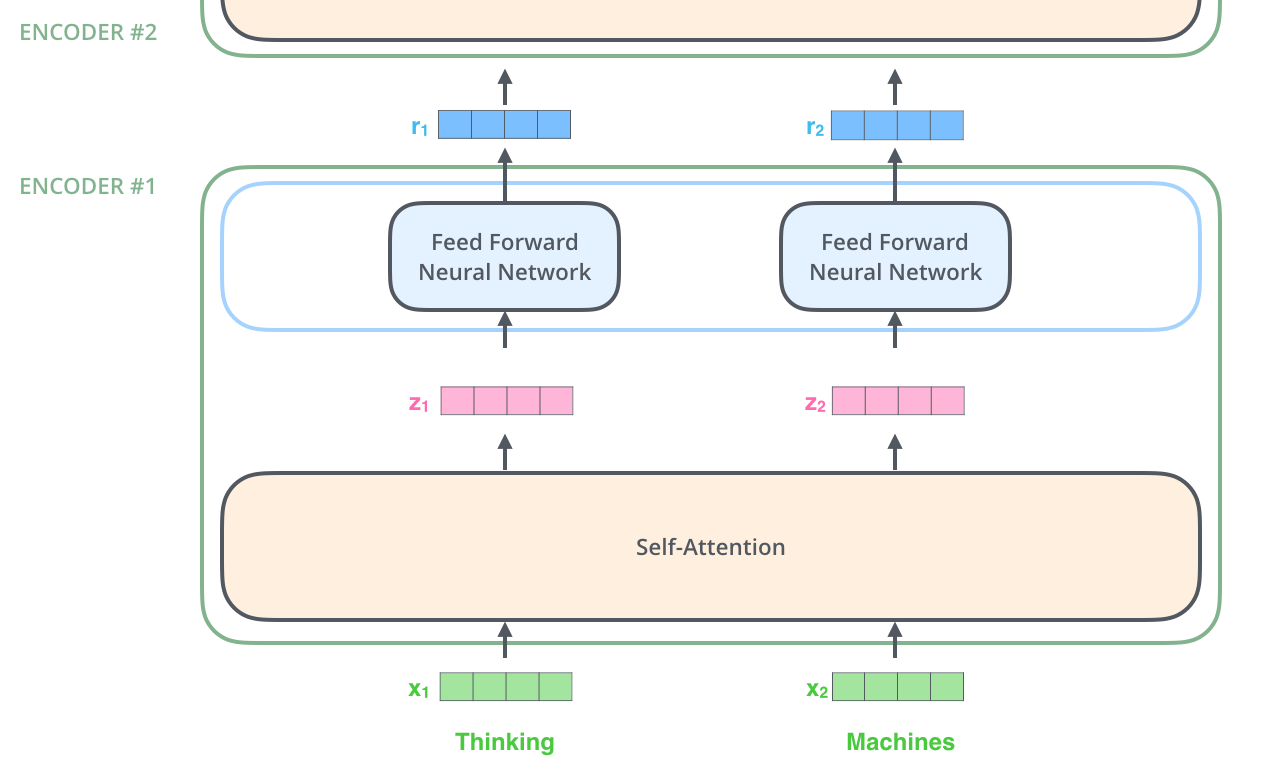
Thinking, Machines 두 개의 단어가 모드 Self-Attention 구조 속에서 Z1, Z2 벡터에 모두 영향을 끼치며 Feed Forward network로 들어간다. 그리고 Feed Forward 구조에서는 각 벡터들이 독립적으로 인코딩되어 r1, r2 벡터에 입력되며 다음 인코더로 해당 벡터들이 들어간다.
Detail in Self-Attention
self-attention에서 사용되는 베터들이 어떻게 구성되는지 자세히 보자.

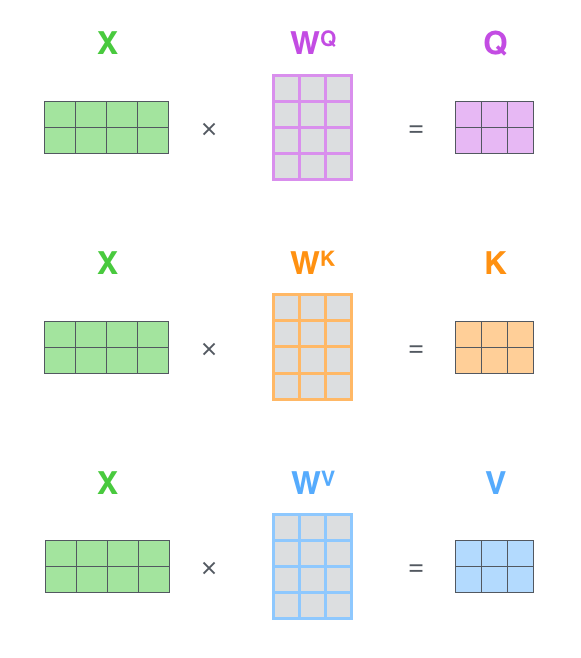
각 입력된 단어에서 Query, Key, Value 세 개의 벡터를 임베딩 방식으로 계산해 생성한다.

그리고 각 단어의 Query벡터, Key벡터 사이의 내적 값을 Score로 지정 후 이를 \(\sqrt{d_k}\)로 나눈 값에 Softmax 연산을 수행한 값을 가중치로 만든다.
그리고 이 값을 Value에 곱하고, 계산되어 나온 v 벡터들의 합을 z1 벡터로 사용한다. 즉 query 벡터 1개로 각 단어들간의 여러 key 벡터와의 내적을 구하고, 이를 softmax 함수로 변환하는 과정에서 q1 벡터와 다른 단어들간의 유사도가 계산되어 z1 벡터에 반영된다.
이렇게 계산된 n개의 K, Q, V 벡터들을 수직으로 쌓아 행렬을 만들고 행렬을 통해 입력한 언어 벡터인 X와 계산하는 과정을 그림으로 나타내면 다음과 같다.

Multi-Head Attention
각각 생성된 여러개의 Z 행렬을 feed forward layer에 전달하기 위해서는 이 Z 행렬들을 합쳐서 하나의 행렬로 만들어야 한다. 왜냐하면 feed forward layer에는 1개의 input만 들어갈 수 있기 때문이다.

따라서 위의 과정으로 나온 여러개의 Z 행렬들을
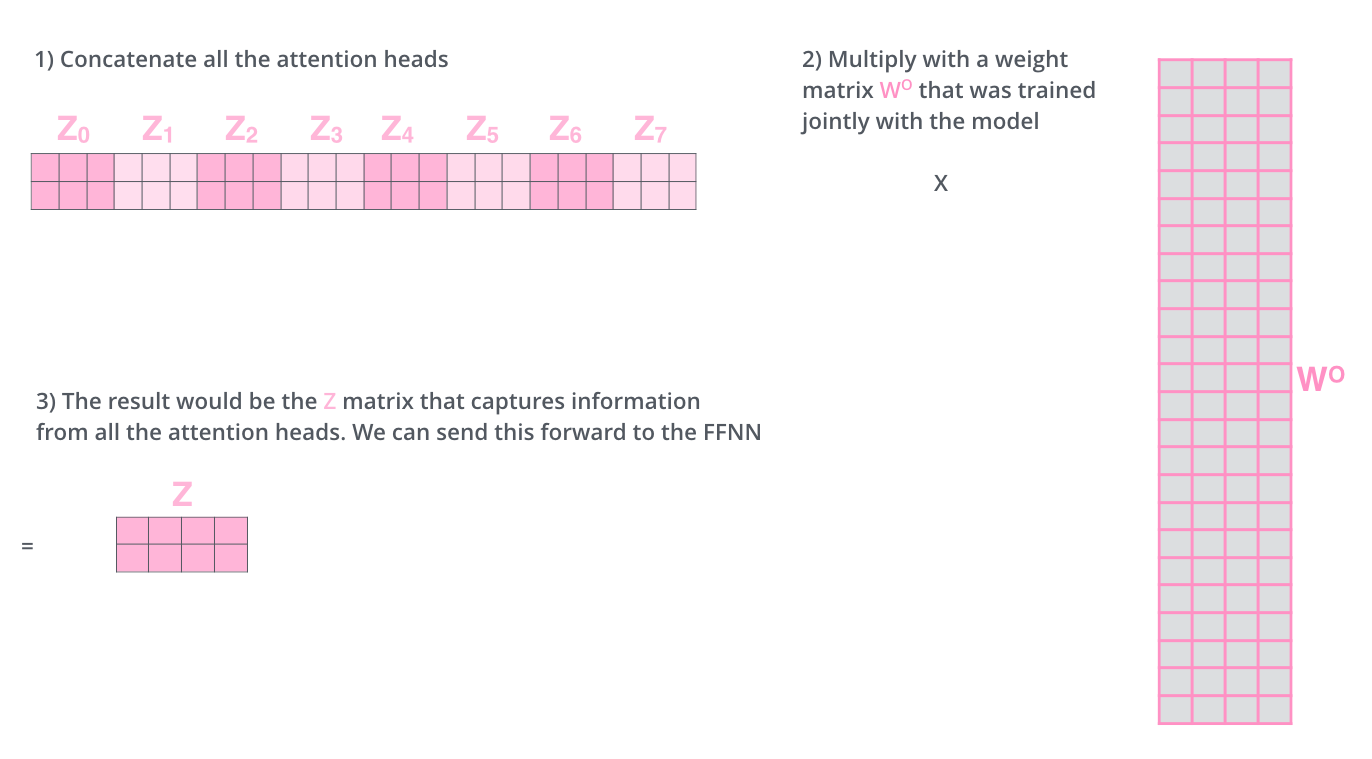
1개의 행렬로 이어 붙인다. 그리고 새로운 weight matrix인 W를 생성해서 만들어진 Z와 곱해준다. 이 과정을 통해 결과적으로 새로운 가중치 행렬 W의 값이 적용된 Z행렬이 나온다.
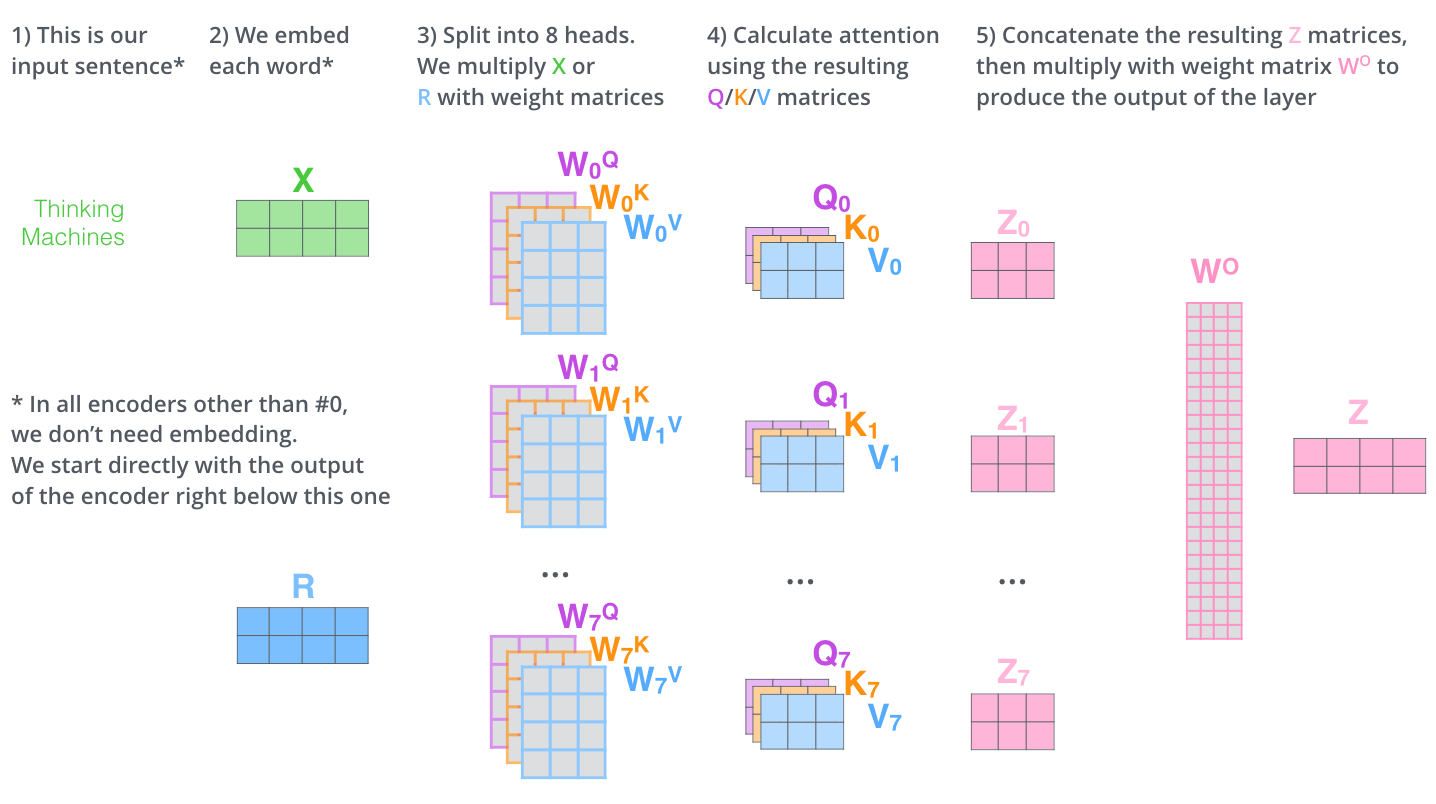
위의 모든 과정이 요약된 그림이다.
Positional Encoding
위의 과정에서 생략된 내용이 positional encoding이다. 문장에서는 단어의 위치가 뜻하는 바가 중요하기 때문에 모델이 올바르게 문장을 해석하기 위해서는 각 단어의 위치에 대한 인코딩 역시 필수이다.

이를 위해서 문장의 위치를 반영한 positional encoding t 벡터를 임베딩할 단어 벡터 x에 더해 이 위치값이 반영된 Embedding with time siganl 벡터를 새로 만든다.

size 4의 인코딩 벡터의 예시이다.
Residuals
각 sub-layer에는 잔차 역시 존재한다. 이것을 해결하기 위해 layer-normalization 단계를 통해 잔차의 영향을 제거한다.
따라서 Add&Normalize 단계가 Feed Forward 전 후에 필요하며 이 과정을 포함한 2개의 인코더, 1개의 디코더가 있는 Transformer 모델을 구조화하면 다음과 같다.

Decoder

인코더를 지난 벡터들은 K, V 벡터로 변환되어 디코더에서 변환된다. 이 과정을 통해 한 단어가 출력이 되고, 역시 positional encoding을 통한 위치 정보가 더해진다.
한편 트랜스포머의 디코더에서는 문장 행렬을 통해 입력을 한 번에 받기 때문에 현재 시점의 단어를 예측할 때, 미래 시점의 단어까지도 참고할 수 있는 현상이 발생한다. 따라서 look-ahead mask를 사용한다.

위의 단어를 디코딩하는 경우 자기 자신보다 미래에 있는 단어들을 참고하지 못하도록 첫 번째 서브층에서 마스킹이 이루어진다.

이런 마스킹을 통해 자기 자신과 그 이전단어들만을 참고할 수 있게 된다.
Reference
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2, Vietnames
jalammar.github.io
'네이버 부스트캠프 학습 정리 > 3주차' 카테고리의 다른 글
| [DL basic] Computer Vision Applications (0) | 2023.03.25 |
|---|---|
| [DL basic] Convolutional Neural Networks (0) | 2023.03.23 |
| [DL basic] Neural Networks / Optimization (0) | 2023.03.21 |