cGAN
주어진 'condition'에 따라서 이미지를 생성할 수 있는 것.

위 이미지처럼 'sketch of a bag' 이 condition으로 주어지고, 이에 맞는 이미지를 생성하게 된다.
일반적인 generative model에서는 다양한 가방하면 떠오르는 이미지들 중에서 랜덤하게 한 개를 그리지만, conditional generative model에서는 스케치에 기반한 가방이 생성된다.
일반적인 GAN과 cGAN의 차이는 Real/Fake를 통한 'Criminal' (Generator) crafts, and "Police" (Discriminator) detects가 서로 counterfeit하며 학습하는 과정은 같지만, Fake 과정에서 C라는 특정 조건을 부여하게 된다.
이런 방식을 통해 이미지를 원하는 다른 스타일로 변경하는 Image Translation이 가능하다.
Super resolution
이미지의 해상도를 개선하는 task.
Input : Low resolution image
output : high resolution immage corresponding to the input image
Ill-posed problem
저해상도 이미지를 고해상도로 복원을 하는 경우 가능한 고해상도의 이미지가 여러 개 존재하는 문제가 있다. 이에 대해 여러 개의 고해상도 이미지 후보들에 대해서도 MSE based Per-pixel loss를 사용해 가능한 후보들에 대한 평균을 취하게 되면 여러 이미지 후보들간의 smoothing이 일어나는 것을 방지할 수 있다.
결과값들에 대한 평균을 내는 경우 회귀에서는 지나치게 smoothing되는 결과가 있어 output이 제대로 나오지 않을 수 있지만, GAN에서는 discriminator가 있기 때문에 괜찮다.
예를 들어 흰색과 검은색을 통해 colorizing하는 task의 경우 회귀의 경우 L1 loss를 통한 흰색, 검은색의 중간값 회색이 결과로 나오지만, GAN 모델에 있어서는 discriminator가 fake image인 gray를 잡기 때문에 흰색 or 검은색의 output이 나온다.
Pix2Pix
img를 통해 img를 생성하도록 학습하는 모델. 기존의 GAN이 noise를 사용해 이미지를 생성하는 것과 달리, 이미지에 대한 스케치를 사용해 이미지를 생성한다.
Pix2Pix의 Loss function의 손실 함수로는 L1 loss + GAN loss를 사용한다. 위 이미지에서 L1 loss만 사용하는 경우는 blur가 심하게 있는 저해상도 이미지를 생성하게 된다. 이 때 cGAN의 loss를 함께 사용하게 된다면, 깨끗한 이미지가 나오는 것을 볼 수 있다.
Pix2Pix의 discriminator로는 path gan이 사용된다. 이 discriminator는 출력값으로 하나의 scalar를 출력하는 것이 아닌 이미지를 분할한 feature map을 출력한다. 또한 cGAN의 loss를 함께 사용하기 위한 cGAN 모델의 일부이기 때문에 조건부 데이터를 이 분할 feature map으로 입력받는다.
CycleGAN
Pix2Pix와 같은 image - to - image 모델로 pair- image를 통해 학습한다. 하지만 같은 이미지에 대해 두 특성을 동시에 갖는 이미지 쌍을 확보하기 어려움에 따라 CycleGAN에서는 pair-image 대신 X 데이터세트와 Y 데이터세트간에 이미지 변환법을 학습한다.
CycleGAN의 loss로는 양방향 모두의 Loss를 사용한다.
도메인 X를 Y로 변환하는 함수 G와 도메인 Y를 도메인 X로 변환하는 F 역시도 학습하며 두 이미지간의 변환을 잘 할수 있도록 학습하는 loss function이 목표이다.
하지만 이 경우 model collapse가 일어나 G : X - Y에서 input X의 값이 어떻든 항상 같은 Y를 출력하게 되는 오류가 발생할 수 있다. 따라서 이를 위해 cycle consistenty loss를 추가로 사용한다.

GAN loss :
G,F : generator
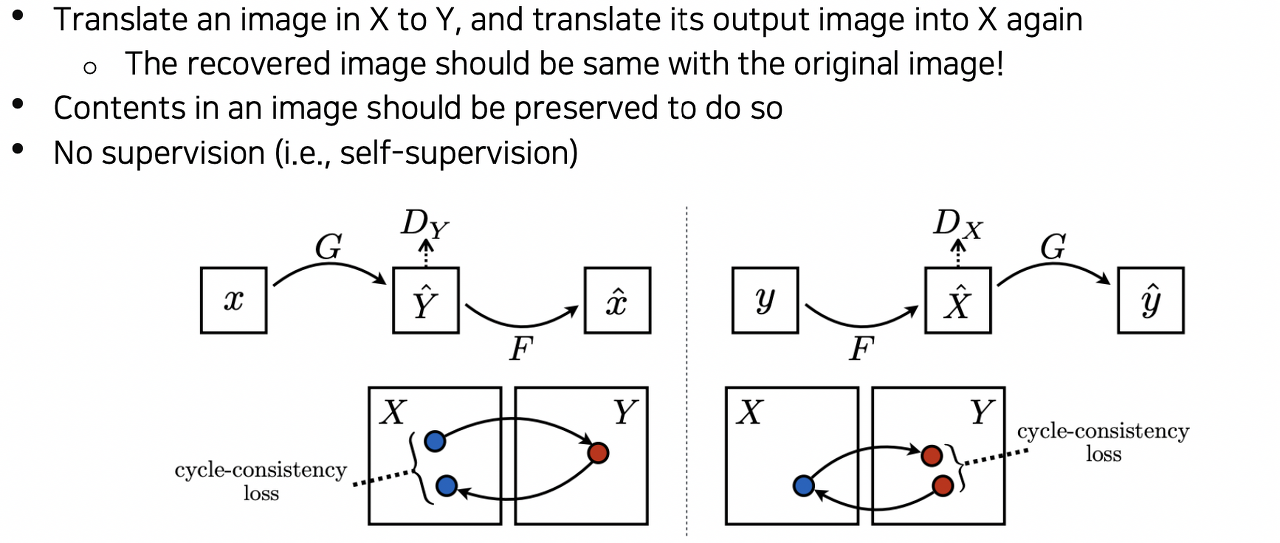
이 방법을 통해 X에서 Y로 변환된 이미지를 다시 X로 돌려 X의 보존량을, Y에서 X 역시 같은 방법으로 보존량을 체크하며 원본의 내용을 얼마나 유지하는지 역시 학습과정에서 사용한다.
Perceptual Loss
perceptual loss는 GAN에서 사용되는 loss로 L1 loss, Gan loss등을 보완하기 위한 손실함수이다.

pre-trained "perception"을 통해 이미지 학습 과정에서 사람과 비슷하게 바라볼 수 있는 perceptual space로 변환시킨다.
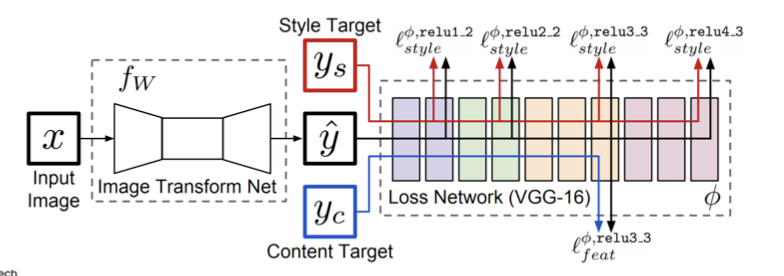
이 학습과정은 어떤 input X에 대해 image transform net을 통과 후, output값 Y를 고정된 Loss Network에 대해 y와 content target을 통과시킨 loss, Feature reconstruction loss y와 style target y를 통과시킨 Style Reconstrucntion Loss를 계산한다.

위 그림에서 Pre-trained loss network를 지나 feature maps of output과 target images 간의 L2 loss를 계산한 것이 Feature reconstruction loss이다.

이 그림에서 Pre-trained loss network를 지나 feature maps에서 생성된 gram matrices와 target image간의 L2 loss를 구한 것이 Style reconstruction loss이다.
Reference
https://deep-learning-study.tistory.com/645
[논문 읽기] 구현 코드로 살펴보는 Pix2Pix(2016), Image-to-Image Translation with Conditional Adversarial Networks
PyTorch 코드와 함께 Pix2Pix를 살펴보도록 하겠습니다. Pix2Pix는 image를 image로 변환하도록 generator을 학습합니다. 예를 들어, generator의 입력값으로 스케치 그림을 입력하면 완성된 그림이 나오도록
deep-learning-study.tistory.com
https://velog.io/@sjinu/CycleGAN
[논문리뷰] Cycle GAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Paper review for Cycle GAN
velog.io
'네이버 부스트캠프 학습 정리 > 5주차' 카테고리의 다른 글
| 5주차 회고 (0) | 2023.04.09 |
|---|---|
| [CV basic] Multi-modal (1) | 2023.04.09 |
| [CV basic] Instance Panoptic Segmentation (0) | 2023.04.08 |