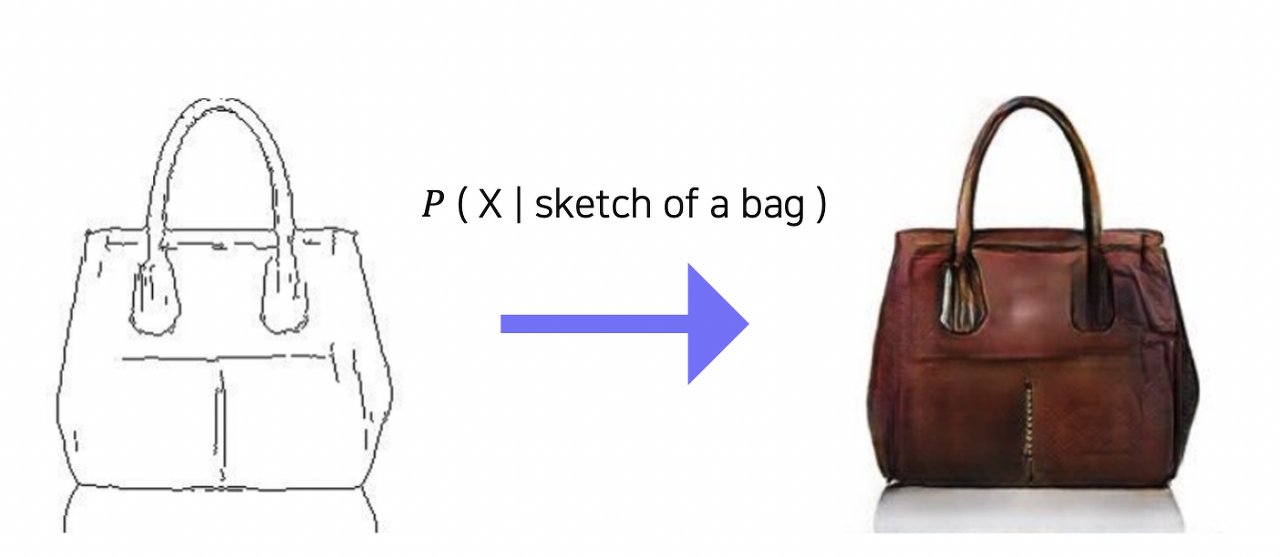
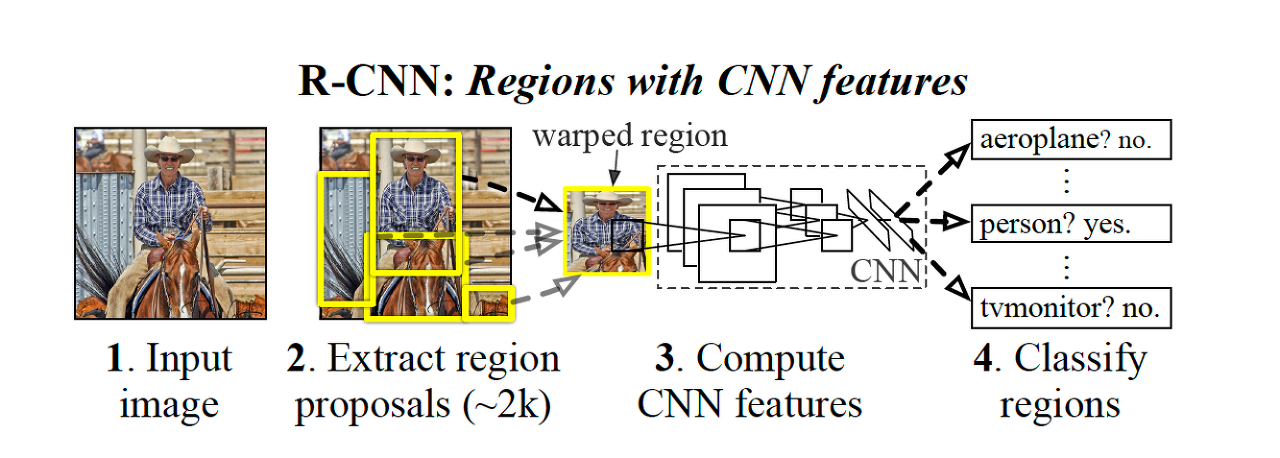
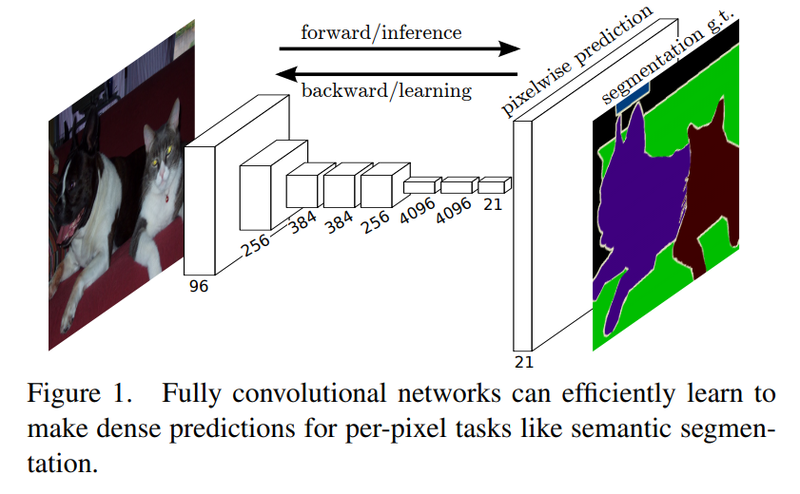
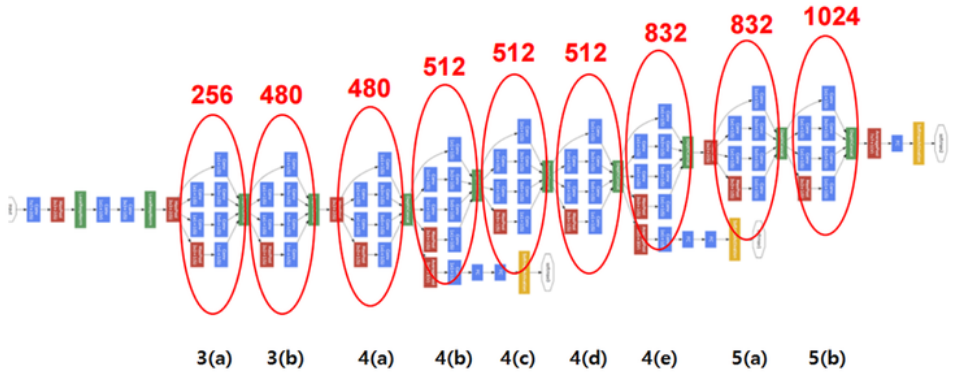
Multi - modal 인간의 지각 능력 (시각, 청각, 후각, 촉각 등)의 여러 지각 능력에서 각 다른 지각의 특성을 갖는 데이터들을 함께 이용해서 학습한 모델을 의미한다. Text data를 사용해 Image를 분류할 수 있는 모델이나, 반대로 Image data를 사용해 그 image를 설명하는 text를 생성하는 모델 등이 해당된다. 하지만 이런 멀티 모달은 학습하기 어려운 특징이 있다. 각 데이터의 유형마다 가지고 있는 정보가 다르기 때문에 정보의 양 뿐만 아니라 feature space 역시 다 다르기 때문에 유형마다의 차이가 크기에 합쳐서 표현할 방법이 필요하다. 멀티 모달의 여러 유형마다 데이터의 난이도, 편향등이 다르기 때문에 같은 비율의 데이터를 사용해 학습을 진행하는 경우 결과로 한..