Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation
수어 번역 KCI를 위해 진행할 연구에서 Baseline으로 사용할 예정인 모델.
Sign Language Transformer
Abstract
gloss 표현을 잘 사용하는 것이 번역 성능을 향상시킨다는 연구에 기반.
end-to-end train이 가능하며 CTC손실을 통해 인식(SLR)과 번역(SLT) 문제를 단일 통합 아키텍쳐로 묶음. GT의 수화 동작의 시작 및 끝 타이밍에 대한 정보가 없이도 인식, 번역을 동시에 해결할 수 있어 더 효율적인 학습이 가능함. 이런 공동 접근 방식은 PHOENIX2014T 데이터셋에 대해 21.8의 BLEU4 score 달성
Introduction
- 수화는 손 뿐만 아니라 얼굴 표정, 입 모양, 머리, 어깨, 몸통의 움직임과 같은 비수동적 특징을 통해 정보를 전달함.
- 수화와 구어의 문법은 매우 다르기 때문에, 객체 간의 관계를 전달하기 위한 방향 및 공간 등 비주얼 정보가 사용되며 간단한 단어-수화 매핑은 존재하지 않음 (NMT와는 다른 멀티 모달의 영역인 이유)
Sign Segmentation
연속된 수어 비디오에서 수화 문장을 탐지하는 과정으로 아직 CSLR을 위한 수화 분할을 활용한 연구가 없음. 연속적인 수어 비디오에서 의미 있는 문장을 자동으로 분리하는 것은 여전히 해결해야 할 일임.
Sign Language Recognition and Understanding
분할 이후 수어에서 전달되는 정보를 인식하고 이해하는 과정. 현재는 수화 gloss와 기타 언어학적 구성 요소를 인식하며 문제를 해결한다. 비디오 데이터인 것을 고려할 때, 매우 복잡한 모델링이 필요하며 현재의 기술은 gloss를 인식하는 것과 날씨 예보와 같은 (PHOENIX2014T) 상황에서 작동함.
Sign Language Translation
수화 언어 번역은 구어 문장을 생성하는 최종 단계임. 다른 자연어와 마찬가지로 수어는 고유의 언어학,문법적 구조를 가지며 자연어와의 일대일 매핑이 되지 않음.
많은 언어 학자들은 gloss와 자연어 간의 매핑을 위한 text-to-text 통계 모델을 사용했지만 글로스는 수화 언어의 단순화된 표현으로 어떻게 처리되어야 하는지 합의되지 않음. 또한, 적합한 데이터셋의 부재로 비디오 기반 SLT는 문제를 겪었음.
Camgoz et al.이 제안한 PHOENIX2014T 데이터셋이 공개되며 SLT를 NMT문제로 접근할 것을 제안하며 첫 번째 end-to-end SLT 모델인 Sign2Text를 실현함.
Sign2Text보다 중간 번역 단계인 gloss를 활용하는 것이 엄청나게 성능을 증가시킨다는 것이 발견되며 Sign2Gloss2Text 모델이 처음으로 CSLR에서 gloss를 recognize하며, 이를 토큰화 계층으로 작용시킴. 글로스를 통해 구어 문장을 생성하는 것이 성능이 훨씬 좋은 이유는 다음과 같음.
- 비디오의 프레임 수 보다 수어 글로스의 수가 훨씬 적음 (태스크 난이도 자체를 낮춤. 비디오 → 구어 에서 글로스 → 구어) 이는 장기 의존성 문제도 개선함
- 수화 문장을 이해하기 위한 직접적인 가이드라인이 부재하기 때문에 중간 감독 없는 수화 이해는 그 성능이 크게 낮음.
이 논문에서는 번역이 SLR 정확도에만 의존하는 two-step pipeline을 피하면서 Transformer를 활용한 모델을 제안한다.
트랜스포머의 encoder-decoder 구조를 통해, sign language recognition과 비디오의 공간적 특징을 활용한 translation까지 jointly 하게 학습할 수 있는 joint continuous sign language recognition and translation problem을 푼다.
트랜스포머 encoder구조에 CTC loss를 활용해 Sign Language Recognition Transformer(SLRT) 구조를 만든 후, 이를 통해 gloss를 예측한다. 이 구조는 수어 비디오의 시공간적 표현을 spatial embeddings으로 추출 후 학습한다. 이후 이 정보들은 Sign Language Translation Transformer(SLTT), 자기회귀 transformer decoder 모델에 fed된다. 이는 한번에 한 단어를 학습하며 구어로 생성하는 것을 학습한다.
간략한 구조는 다음과 같다.
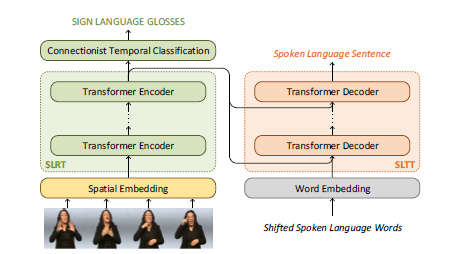
이 논문의 기여는
- 구어로 번역을 제한하지 않으며 Gloss의 supervision power를 활용하면서도 CSLR과 SLT의 새로운 멀티태스킹을 공식화 함
- CSLR과 SLT 모두에서 최고의 결과를 달성하며 Transformer의 첫 번째 성공적인 적용
- 이 분야의 향후 연구를 안내할 수 있는 다양한 새로운 기준선 결과의 범위 제안.
Sign Language Transformers
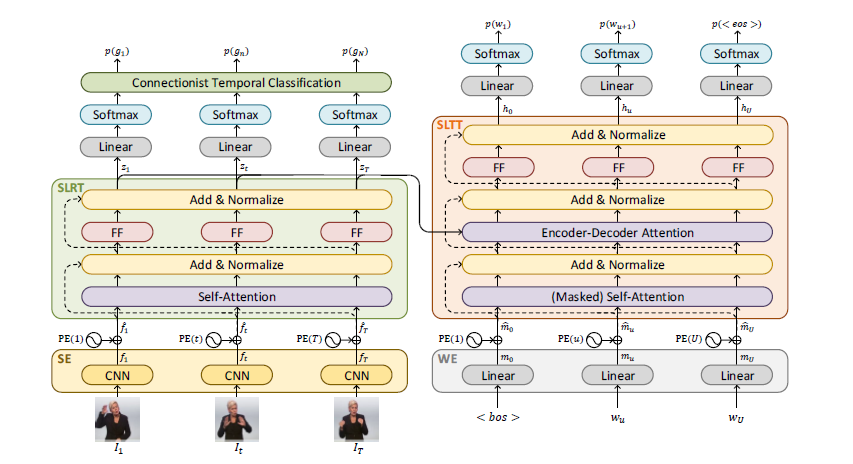
SLT (Sign Language Transformers)는 수어 비디오를 gloss로 인식하고 구어로 번역하는 것을 동시에, end-to-end로 학습한다.
T의 프레임을 가진 비디오 V(I1,I2, .. IT)에 대해 N개의 글로스를 가진 G(g1,…gN)과 U개의 단어를 가진 구어 문장 S(w1, … wU)에 대해 조건부 확률 p(G|V) 와 p(S|V)를 학습하는 것이 목표이다.
비디오 프레임 수 T가 글로스 N개, 단어 U개에 비해 엄청나게 많은 것이 당연하기 때문에 여러 도전이 요구되며 비디오 V와 구어 S사이의 매핑 역시 다른 어휘, 문법 규칙 등에 의해 매핑이 비단조적임.
SLT에 대한 이런 sequence-to-sequence 를 도전하는 방식은 두 그룹으로 나뉜다.
첫 번째 그룹 : 문제를 두 단계로 나누어 CSLR을 첫 단계로, 그 후 text-to-text 번역 작업으로 진행하려고 함. CSLR을 거쳐 gloss를 먼저 얻은 후, NMT 모델을 활용해 글로스에서 p(S|G)를 학습했음. 하지만 이 방법은 gloss 표현에서 정보 병목 현상이 생긴다. gloss는 비디오에 있는 정보의 상실이 이루어진 간단화된 표현이며, 글로스의 질에 따라 글로스의 수준만큼만 모델이 좋아질 수 있기 때문이다.
두 번째 그룹 : p(S|V)를 바로 학습하는 방법으로, gloss에 의존하지 않으려 한다. 하지만 이 방법은 현재의 적은 데이터셋에 의해 충분한 데이터셋과 정교한 아키텍쳐가 없기 때문에, 오히려 상당히 낮은 성능을 보인다.
이런 문제를 해결하기 위해 P(G|V)와 P(S|V)를 end-to-end로 jointly 하게 학습하는 것을 제안한다. 통합된 모델을 위해 트랜스포머 네트워크를 사용하며, CTC손실을 통해 gloss supervision을 SLRT 인코더에 즉각 주입하며 네트워크가 보다 더 의미있는 시공간 표현을 학습하게 한다. 이후 디코더에선 SLTT를 통해 한 번에 하나의 단어를 예측하게 한다.
Spatial and Word Embeddings
source and target token, 즉 비디오 프레임과 구어 언어 단어를 클래식한 NMT 파이프라인에 따라 임베딩을 진행한다.
linear layer를 통해 훈련 동안 처음부터 초기화되며 one-hot-vector 표현을 더 밀집된 공간으로 투영한다.
비디오 프레임 임베딩에서는 SpatialEmbedding을 사용하며, 각 이미지는 CNN을 통해 전파된다. 수식은
다음과 같다.
트랜스포머는 또한 recurrence 나 CNN구조가 없기 때문에 위치 정보가 부족해 PositionalEncoding을 따른다. 이는 트랜스포머 논문에서 사용한 방법과 같다.
이 Encoding은 각 시간 단계에 대해 위상이 이동된 사인파 형태의 고유 벡터를 생성하는 사전 정의된 함수로, 트랜스포머 구조에선 각 요소가 위치한 순서에 대한 정보를 포함하게 된다.
Sign Language Recognition Transformers
이런 fhat 값들을 통해 transformer encoder model을 학습한다.
positional encoding까지 진행 된 공간 임베딩 fhat을 사용해, SLRT에 대한 입력은 비디오 프레임 표현 사이의 문맥적 관계를 학습하는 Self-Attention층에 의해 모델링된다. 이후 이 값은 non-linear point-wise feed forward layer를 통과해 residual connection과 정규화를 거치며 훈련 연산이 진행된다. 이 과정은 수식으로 다음과 같다.
\(z_t = \text{SLRT}(\hat{f}t | \hat{f}{1:T})\)
zt 는 시간 단계 t에서 SLRT에 의해 생성된 프레임 It의 시공간적 표현이며, 주어진 모든 비디오 프레임의 공간적 표현에 대해 t 시점의 정보이다.
중간 gloss supervision을 통해 네트워크가 수어를 이해하고, 번역을 돕는 수화 표현을 학습하도록 유도한다. 즉 SLRT가 P(G|V)를 모델링하고 글로스를 예측하도록 훈련하며, 비디오 프레임에 대해 일대다 매핑을 가지지만 (글로스보다 프레임의 수가 훨씬 많음) 같은 순서를 공유하게 된다.
SLRT를 훈련하는 방법으로 프레임 레벨에 따른 annotation을 통한 크로스 엔트로피 손실이 있지만, gloss는 이정도 정밀도를 갖지 않기 때문에 CTC와 같은 seq2seq 학습 손실 함수를 사용한다.
시공간적 표현인 z에 대해 선형 투영 계층을 따라 softmax를 통해 프레임 레벨의 gloss 확률 P(gt|V)를 얻는다. 이후 CTC를 통해 가능한 모든 V에서 G로의 정렬을 종합함으로써 P(G|V)를 계산한다. 그 식은 다음과 같다.
\(p(G|V) = \sum_{\pi \in B} p(\pi|V)\)
여기서의 pi는 경로이며 B는 G에 해당하는 모든 경로 집합이다. 여기서의 P(G|V)를 사용해 CSLR 손실을 계산한다.
\(L_R = 1 - p(G^*|V)\)
CSLR 손실인 LR은 다음 식과 같으며, G*은 GT 글로스 시퀀스이다.
Sign Language Translation Transformers
최종 목표는 구어를 생성하는 것으로, SLRT에 의해 학습된 시공간적 표현 z를 활용하는 트랜스포머 디코더 모델인 SLTT 역시 훈련하는 것을 제안한다. 타겟 구어 문장 S 앞에 특별한 시작 토큰인 <bos>를 추가하며, 위치 인코딩 된 단어 임베딩을 추출한다. 이 임베딩은 mask 처리된 self-attention 층으로 전달되며 SLRT에서의 메인 아이디어와 비슷하지만, 마스크를 적용해 자신의 선행 토큰만을 사용할 수 있도록 보장하는 점이 다르다. (문장 뒷부분 컨닝 방지)
SLRT와 SLTT의 self-attention에서 추출된 표현들은 결합되어 encoder-decoder attention 모듈에 제공된다. 이 모듈의 출력은 non-linear point-wise feed forward layer에 전달되어 SLRT와 비슷하게, residual connection과 정규화를 거치며 이런 과정은
\(h_{u+1} = \text{SLTT}(\hat{\mu}u, \hat{\mu}{1:u-1}; z_{1:T})\)
과 같이 표현된다. 좌측 식은 시간 스텝 u에서 디코딩된 다음 단어의 표현이며 우측의 SLTT를 통해 시공간적 표현인 z와 이전에 디코딩된 단어들의 임베딩인 u:u-1을 통해 이 표현이 생성된다.
SLTT는 문장 종료 토큰인 <eos>를 생성할 때까지 한 번에 하나의 단어를 생성하도록 학습되며 이는 P(S|V)를 순서대로 분해하여 학습하는 것이다.
\(p(S|V) = \prod_{u=1}^{U} p(w_u | h_u)\)
각 단어에 대한 교차 엔트로피 손실은
\(L_T = -\sum_{u=1}^{U} \log p(w_{u} | h_u)\)
이며 LT는 전체 타겟 시퀀스에 대한 교차 엔트로피 손실로,타겟 시퀀스의 길이 U에 대해 wu는 시간 u에서의 실제 타겟 단어, hu는 모델의 예측 단어 포현으로 hu 상태에서 wu를 예측할 조건부 확률의 U까지의 합에 음수를 취한 것이 손실이다.
전체 로스는 조정 파라미터 람다를 곱한 LR + LT로 이루어진다.
'논문리뷰' 카테고리의 다른 글
| Faster R-CNN (0) | 2023.12.23 |
|---|---|
| Attention Is All You Need (0) | 2023.04.24 |
| Generative Adversarial Nets (GAN) (1) | 2023.04.22 |