
모든 것이 끝났다.
no_recent_20_game 항이 True인 사람들은 다른 데이터를 수집하지 않았고, 결측치로 들어가 있어 610명이 나온다. 이들은 그냥 만나고 싶지 않은 사람으로 분류한다. 롤을 20판도 하지 않은 자들은 나의 '팀' 에서 박탈이다.

내가 잡은 기준이다. 이 두 부류로 나눌 예정이다

전체 승률, 최근 20판 승률이 필요하다. 이들은 이미 구해진 데이터에 식을 세워서 간단하게 표에 추가 가능하다.

세 그룹으로 분류했다. 위 기준으로 두 부류로 나누기엔 NaN값이 들어간 부류를 정하기 애매했다. 그래서 최근 20판을 하지 않았더라도 전체 승률이 50%를 넘기는 사람들은 잘 하는 사람과 못 하는 사람의 사이인 그냥 중간 계급에 넣기로 했다.
변수로 랭크를 추가하기로 했다. 골드 1~4 구간의 정보도 넣어 주어야 분류 모델이 더 좋을 것 같았다.

라벨 인코더로 범주형으로 나눔과 동시에 train/test 데이터 분할도 진행했다.
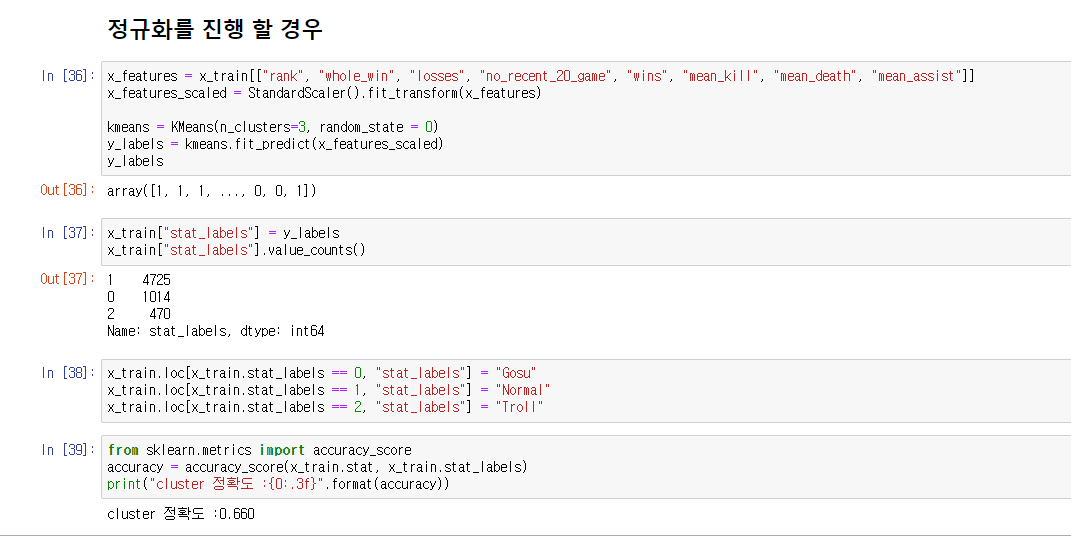
정규화를 진행하지 않았던 경우 K-means clustering 정확도가 0.560으로 56%였다. 그래서 정규화를 진행한 결과 0.660으로, 괜찮은 정확도가 나왔다.
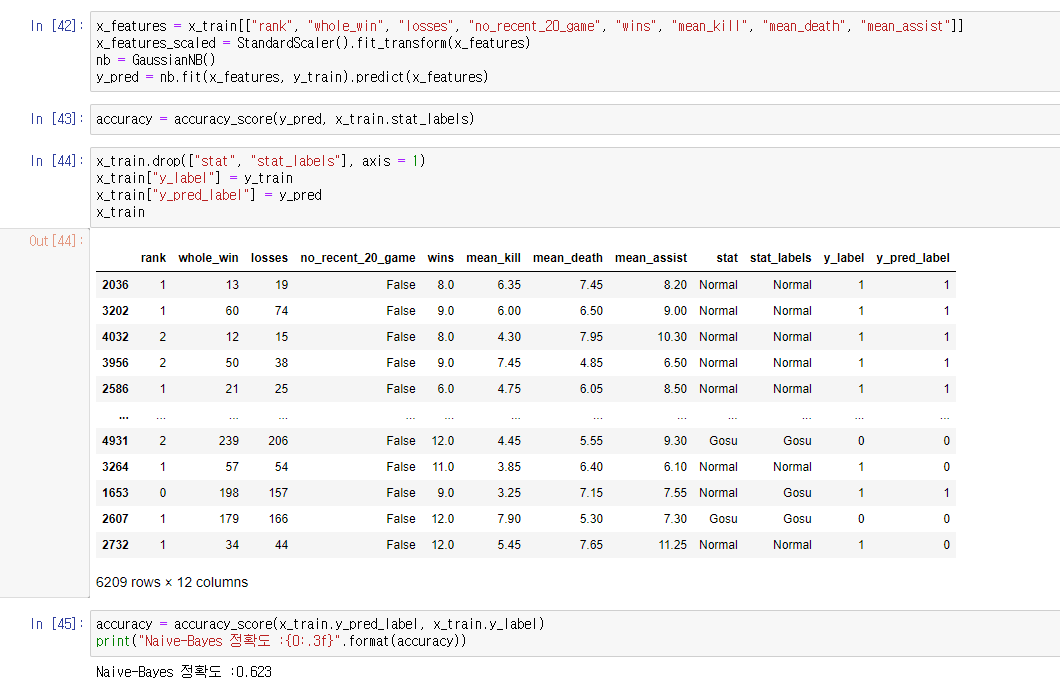
다른 모델로 Naive-Bayes 분류 모델을 통한 분류 결과는 0.623으로 62.3%의 정확도를 보였다. K-mean이 더 정확도가 좋았다.
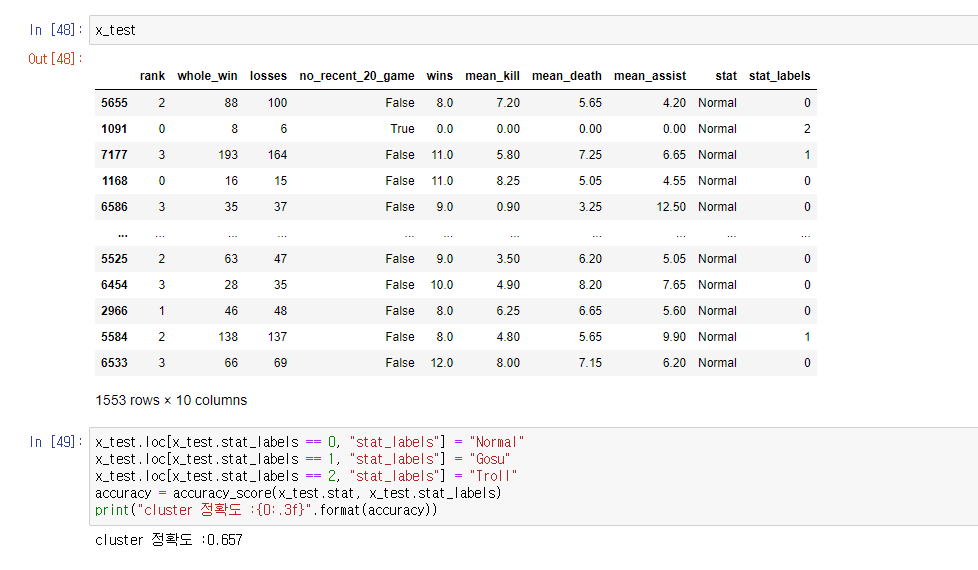
test data에 적용한 결과 65.7%의 정확도를 보였다.
이제 롤할때 우리팀 전적을 긁어서 분류기에 넣으면, 65.7% 확률로 그래도 얘가 어떤 사람인지는 파악할 수 있다.
아쉬운 점은, 애초에 잘 하는 사람과 못 하는 사람의 기준을 내 잣대로 정한 것이기 때문에 너무 주관적이다. 따라서 Gosu로 분류된 것이 진짜 고수는 아니라는 것이다. 물론, 내 기준인 전체 승률 50%이상, 최근 승률 55%이상, 좋은 kda등으로 잘할 확률이 상당히 높은 사람이다.
후기
어쩌면 좀 허점이 많은 분류 프로젝트였지만, 이 모든 것을 혼자서 진행하느라 확실히 api를 통해 데이터를 크롤하는 것과, 따온 데이터들을 핸들링하는 능력이 많이 늘었다. 넘파이, 판다스랑 확실히 많이 친해진 계기가 되었다.
'프로젝트 > 빅데이터분석 기말 프로젝트' 카테고리의 다른 글
| 롤 분류기 (2) - 데이터 수집 노가다 (0) | 2022.06.28 |
|---|---|
| 롤 분류기 (1) - 라이엇 api를 사용해 정보를 긁어보자. (0) | 2022.05.26 |