EAST 모델
bounding box 좌표를 맞추는 것을 Regression 모델로 접근한 모델.
FCN을 변형한 구조로 각 픽셀이 단어 영역 내에 있을 확률인 score map,
각 단어 box를 추정 후 픽셀과 box 4개 변 사이의 거리를 의미하는 거리 정보, box가 회전한 각도 정보 등을 출력하고 이를 선형결합한 형태의 loss를 활용해 학습한다.
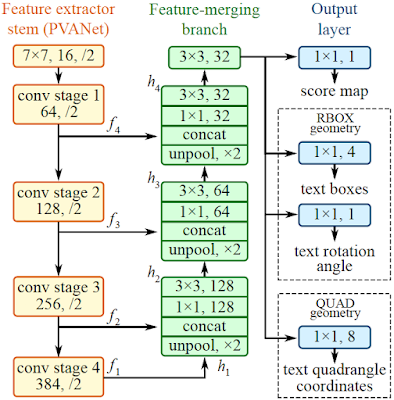
U-Net의 모양과 비슷한 FCN을 사용해 Conv채널을 증가시키며 이미지를 축소시키는 Encode과정을 거치고, 1/32로 축소한 Feature map을 생성한다. 이후 Decode 과정에서 이미지 사이즈를 키우며 복원하는데, 앞에서 생성된 Feature map들에 대해 Concat를 진행하며 글자가 있는 위치를 더 잘 확인하게 한다. 이후 최종적으로 Input size의 1/4 정도의 Score map이 생성된다.
Semantic Segmentation을 위해 제안된 FCN을 사용해 FC layer를 지나기 전 위치 정보를 보존하는 feature map들을 활용해 Transpose Convolution을 통해 Input과 비슷한 사이즈로 복원한다.
이 과정을 통해 생성된 Score map은 map의 모든 픽셀마다 어떠한 값이 부여된다.
Create Score map
이미지의 ‘영수증’ 단어 부분을 추론하는 과정에 대해 설명.

원본 이미지의 일부분을 잘라옴.
이후 위 이미지의 절반 사이즈로 검은색으로 채워진 Score map을 초기화한다.
Image size: (281, 397, 3)
Score map size: (140, 198, 1)Center Region with box shrinking
EAST는 bounding box의 center region에 대해 segmentation을 수행함.
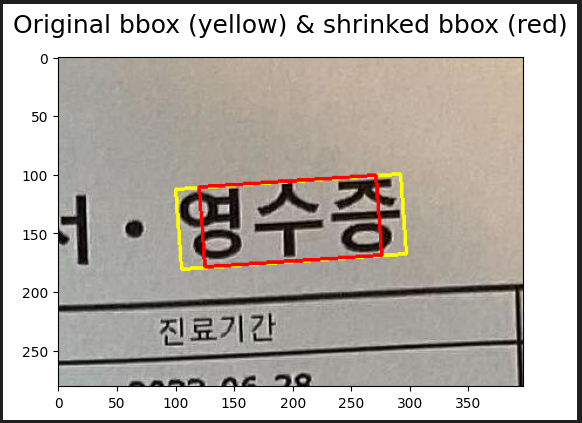
가로 부분을 30% 줄이고, 세로 부분을 3
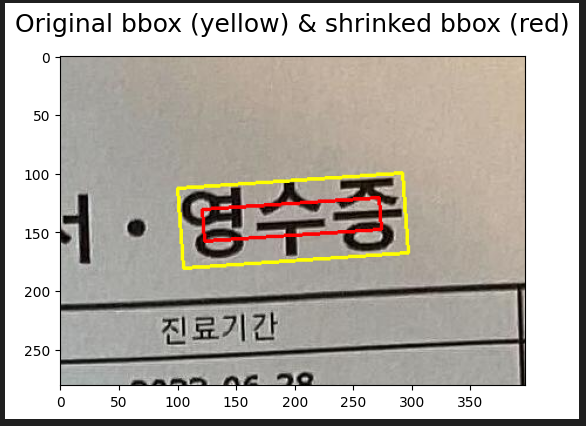
0% 줄이며 순차적으로 진행.
poly = np.round(MAP_SCALE * shrunken_bbox).astype(np.int32)
cv2.fillPoly(score_map, [poly], 1)
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(ROI_FIG_SIZE[0] * 2, ROI_FIG_SIZE[1]))
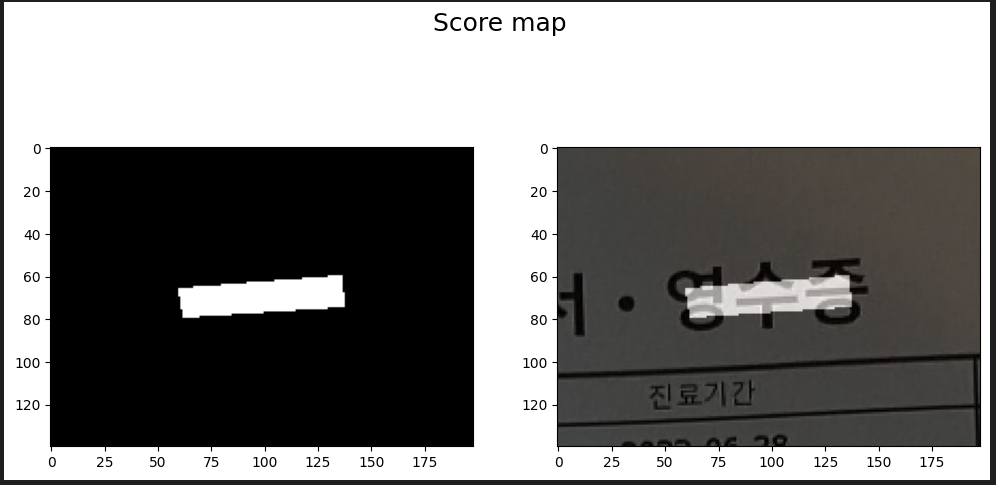
plt.suptitle('Score map', fontsize=18, y=0.97)
axs[0].imshow(score_map, cmap='gray')
axs[1].imshow(get_superimposed_image(cv2.resize(roi_patch, dsize=(map_w, map_h)), score_map, heatmap=False))fillpoly 함수를 사용해 빨간색 줄어든 박스 영역에 대한 Score map 생성.
Geometry map
크기는 이미지의 1/2
상/하/좌/우 방향으로 픽셀로부터 글자 박스 경계선까지의 거리를 예측하는 채널 d1, d2, d3, d4
글자의 각도를 예측하는 theta.
이 과정은
- Geometry Map 초기화
- BBOX의 각도를 계산
- BBOX 영역을 덮는 RBOX를 찾음
- 찾은 RBOX와 각도를 활용해 distance map, angle map을 생성
순서로 이뤄짐

5개의 map을 Score map 초기화와 같이 초기화.

bbox를 주어진 각도로 돌리며 이 돌아간 박스를 담고있는 RBOX를 찾는다.
GT bbox를 RBOX로 변환하기

맨 왼쪽의 오렌지색 박스는 theta값 -4도 만큼 돌아간 bbox이고, 이 주황색 박스를 가장 tight하게 잡는 핑크색 박스를 구한다. 그리고 이를 다시 돌아갔던 theta값 만큼 (+4도) 돌려주면 3번째 이미지의 핑크색 박스가 나온다.
위 이미지의 경우 주황색 박스와 핑크색 박스의 차이가 거의 없어 차이가 나지 않는다.

이 이미지의 노란색 점선 박스와 핑크색 실선 박스의 차이라고 보면 된다.
기존 bbox를 회전한 노란색 점선 박스를 임의로 생성 후, 이를 덮는 핑크색 박스를 사용하는 개념이다.
이 과정을 통해 theta값, Rbox, 노란색 박스까지 얻었다.
Distance map 생성과정
- 아무것도 없는 canvas에 linear하게 증가하는 distance map을 생성한다. (angle, rbox의 정보 x)
- angle theta 정보를 사용해 distance map을 회전시킨다.
- 돌아가있는 distance map을 box정보를 사용해 box 위치로 옮긴다. (min/max x, min/max y 활용)
- shrinked bbox를 사용해 score map영역에 해당되는 pixel들에만 distance map을 생성한다.
과정 1.
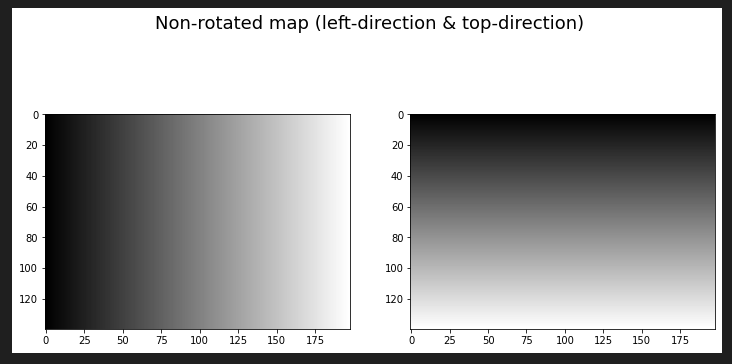
캔버스에 linear한 distance map을 생성한다. 왼쪽 캔버스는 좌측 변에 대한 distance map, 오른쪽은 윗변에 대한 distance map이다.
왼쪽의 가운데 픽셀은 100의 값을 지니므로, 좌측 변까지의 거리가 100이 필요하다. 따라서 100의 밝기를 가진 픽셀이다. 반면 왼쪽 끝의 0에 있는 픽셀들은 이미 좌측 변에 있기 때문에 0의 거리가 필요하다. 따라서 0의 검정색 픽셀을 가진다.
오른쪽 역시 같은 원리이다. 이렇게 네 변에 대한 distance map을 생성한다.
과정 2.

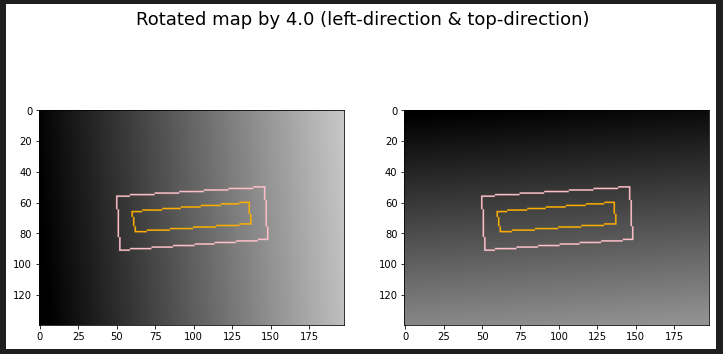
angle theta인 값 4를 사용해 distance map을 회전시킨다.
위의 distance map이 약간의 기울기를 가진 채로 변경된다.
과정 3.
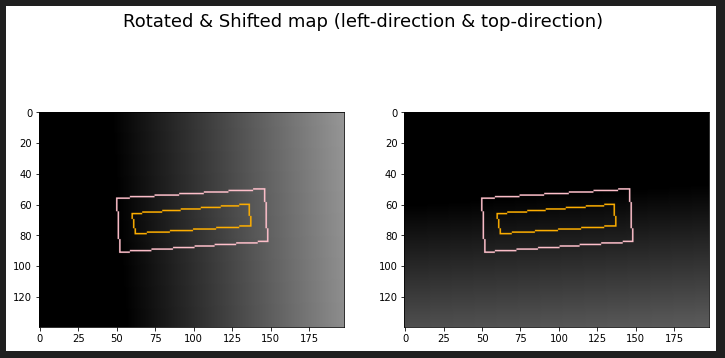
여기에 shift를 적용하면 분홍색 박스의 좌측 변이 임계치가 된다. 따라서 좌측 변보다 밖에 있는 영역은 음수가 되므로, 이를 0으로 saturate 시킨다. 따라서 분홍 박스의 좌측 변보다 옆에 있는 부분은 0이 되며, 우측의 픽셀들은 좌측 변까지의 거리를 나타내게 된다.
과정 4.

이후 score map과의 합성을 통해 score map의 관심 영역 부분에만 distance 값들을 생성해주며, 나머지 필요없는 부분은 모두 0으로 변경한다. 여기서 score map의 관심 영역은 글자 bounding box의 center region으로, shirnk 된 박스이다.

4개의 방향에 대한 distance map

또한 theta에 대한 정보도 geometry map에 나타내준다.
따라서 위의 4 방향에 대한 거리 정보와, theta 값 까지 5개의 학습할 수 있는 map이 생긴다.
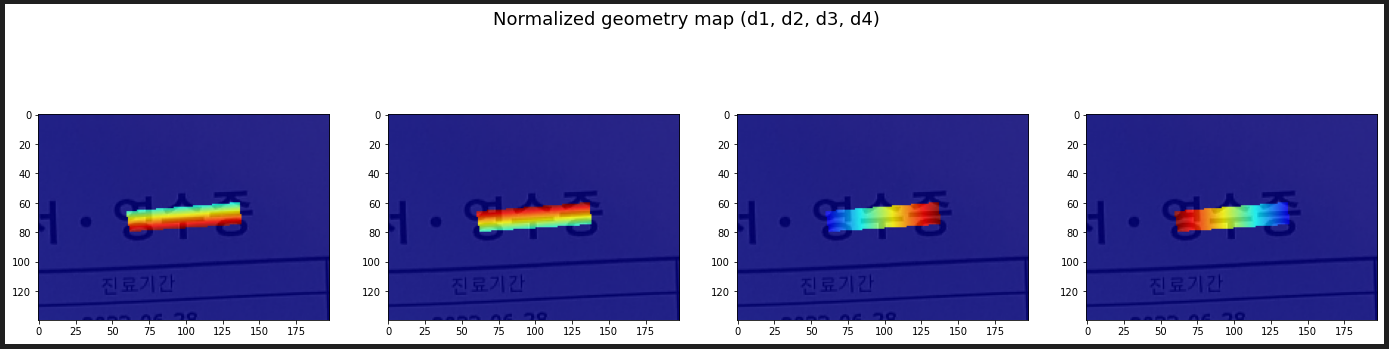
흑백 이미지에서 RGB 이미지로 정규화 한 결과.
붉은색일수록 더 많이 이동해야 하며, 파란색으로 갈수록 더 적게 이동해야 한다는 의미를 가진다.

전체 영역에 대한 GT maps. 각 방향에 대한 distance map과 마지막 보라색 이미지는 theta 정보를 가진 맵이다. 대부분이 horizontal이라 같은 값을 가지기 때문에 단색으로 보인다.

학습 과정에서 위의 이미지들이 score map의 정보를 사용하지 않고 나타난 distance map들의 정보이며, score map을 사용해 elementalize multiple을 적용하면 아래처럼 깔끔하게 된다.
학습 과정?
- confidence한 score map영역을 찾는다. (예시에선 center region)
- valid 한 score map에 위치해있는 각 point들을 모두 iterate하며
- point에 위치한 distance map(d1, d2, d3, d4)를 사용해 정방향인 box를 찾는다.
- point에 위치한 angle map(theta)를 사용해 정방향의 box를 추출함.

위와 같은 사진에서 상단의 빨간색 픽셀 하나에 대한 1~2 과정이 끝난 것이 파란색 박스이다.

따라서 하얀색 score map의 모든 픽셀이 파란색 박스를 가지게 되면 몇백개의 파란색 박스가 다음과 같이 생긴다.
3. NMS를 통해 최종 박스를 찾는다.
NMS이후 정답인 파란 박스만 남는다.