GoogLeNet
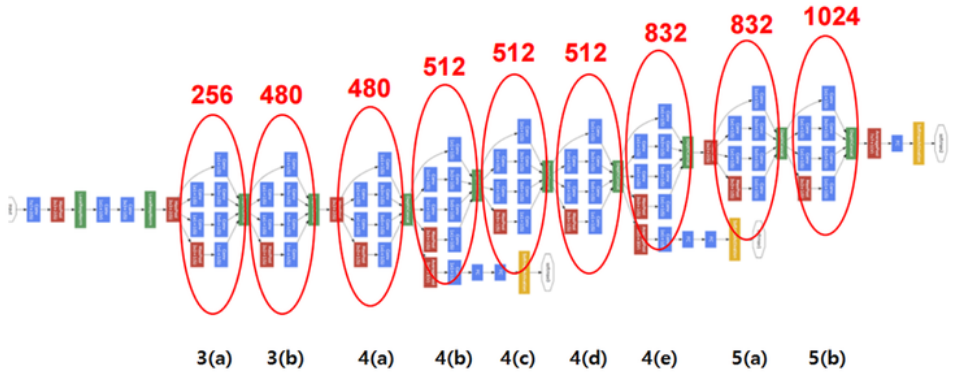
GoogLeNet의 전체 구조. 동그라미 친 부분이 Inception module이며, 첫 부분은 Vanilla CNN이다.
Inception module
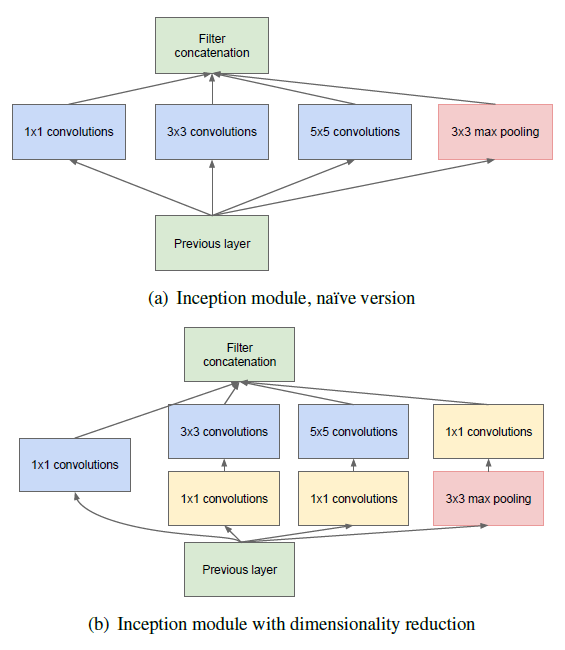
(a)는 1x1 conv를 통한 차원 축소를 진행하지 않은 Inception module이며, (b)는 차원 축소를 진행한 모듈이다.
Inception module은 1x1, 3x3, 5x5 conv filter 이후 3x3 max pool을 진행한 후 모든 필터를 합쳐서 뱉어낸다.
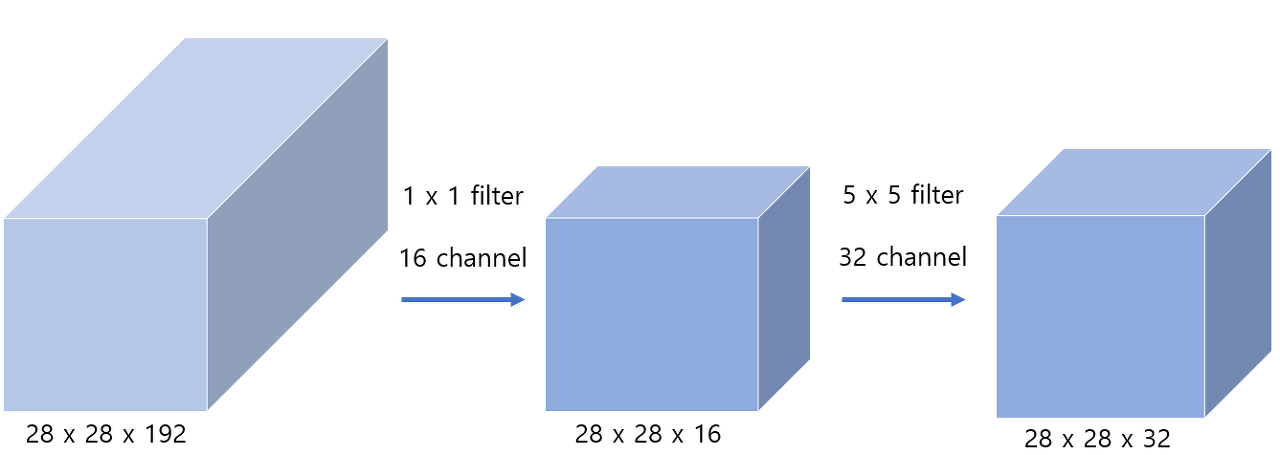
(b)의 차원 축소는 1x1 conv filter의 bottleneck 구조로 이루어진다.
이런 구성으로 이루어진 Inception module을 쌓아서 이루어진 구조이며 그 아래엔 Auxiliary classifiers가 있다.
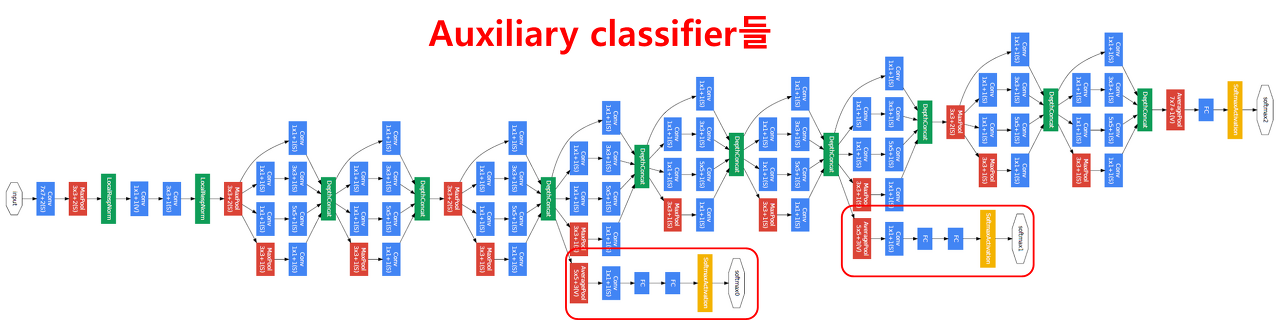
Auxiliary classifier는 네트워크의 깊이가 깊어지며 생기는 vanishing gradient 문제를 피하기 위해 만들어진 과정이다. 역전파가 흐르는 과정에서 gradient가 소실되는 것을 방지하기 위해 중간 과정에서 역전파를 새로 주입해주는 주사기같은 역할을 한다. 이 구조는 training 구간에만 사용되며, test 구간에서는 사용하지 않는다. (test 때는 학습이 필요 없기에 역전파가 필요가 없다.)
마지막에 1개의 FC Layer를 통해 최종 분류결과를 만든다.
ResNet
Revolutions of depth.
말 그대로 네트워크를 엄청나게 깊게 쌓을 수 있는 메커니즘을 제안한 논문.

Residual Neural Network의 줄임말로 잔차(residual)을 사용해 레이어의 인풋을 다른 레이어로 곧바로 건너 뛰는 과정을 통해 층의 깊이를 엄청나게 깊게 만들고 성능이 저하되지 않게했다.
Degradation problem
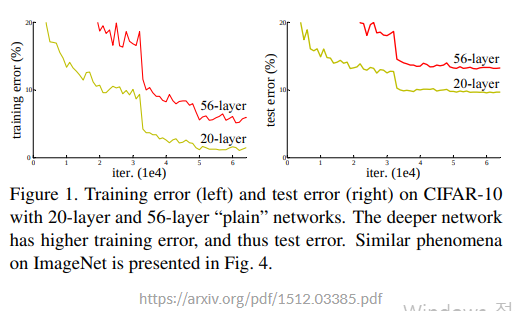
기존 네트워크에서 layer의 깊이를 깊게 쌓을 수 없는 이유로는 Degradation problem이 있다. 이는 레이어가 깊어지는 경우 모델이 수렴했음에도 최적화 이슈로 training/test error가 커지는 현상이다. 이 현상의 원인으로는 과적합이라고 많은 사람들이 생각했지만, ResNet 논문에 따르면 과적합인 경우 training error는 작아야 하는데 이 문제가 발생한 경우 56층의 layer가 20층의 layer보다 training/test error가 모두 낮은 점을 들어 이것이 오버피팅이 아닌 최적화로 인한 문제라고 밝혔다.
Residual block
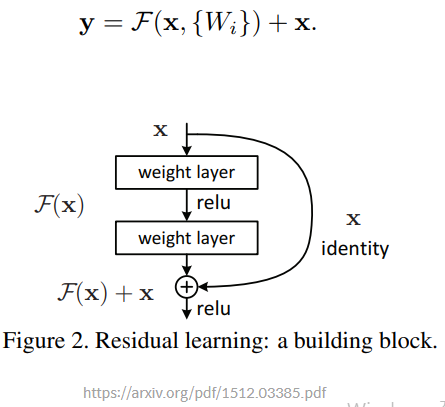
위와 같은 'shortcut connection' 을 통해 degradation 문제를 해결할 수 있다.
학습 할 레이어 \(H(x)\)를 \(F(x) + x\)의 구조로 만드는 경우 레이어의 입력값 x가 더해지는 구조로 만들어지기 때문에 Vanishing gradient로 인해 \(F(x)\)의 값이 0이 되더라도 학습할 내용인 \(H(x)\)는 x가 더해진 상태이기 때문에 성능이 저하되지 않는다. 그리고 모델이 학습하며 가중치를 조절해야할 \(F(x)\)는 \(H(x)\)에서 x를 뺀 형태이기 때문에 잔차의 형태를 띈다. 따라서 residual neural network라는 이름이 생긴 것.
ResNet34 구현
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True, norm="bnorm", relu=True):
super().__init__()
layers = []
self.norm = norm
self.conv1 = nn.Conv2d(in_channels = in_channels, out_channels = out_channels, kernel_size = kernel_size,
stride = stride, padding = padding, bias = bias)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(in_channels = out_channels, out_channels = out_channels, kernel_size = 3,
stride = 1, padding = padding, bias = bias)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace = True)
def forward(self, x):
if self.norm is None:
x = self.conv1(x)
x = self.relu(x)
else:
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
return xconv filter 구현. 2개의 CNN을 구조로 사용한다.
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=True, norm="bnorm", short_cut=False, relu=True, init_block=False):
super().__init__()
layers = []
if init_block:
init_stride = 2
else:
init_stride = stride
self.resblk = ConvBlock(in_channels = in_channels, out_channels = out_channels, kernel_size = kernel_size,
padding = padding, bias = bias, stride = init_stride, norm = norm, relu = relu)
self.downsample = nn.Sequential(
nn.Conv2d(in_channels = in_channels, out_channels = in_channels*2, kernel_size = 1, stride = init_stride, bias = bias),
nn.BatchNorm2d(in_channels*2)
)
self.short_cut = short_cut
def forward(self, x):
if self.short_cut:
x_ = self.downsample(x)
return x_ + self.resblk(x)
return x + self.resblk(x)Resblock는 convblock + convblock + residual connection 구조로 이루어진다. 34층의 구조에서는 Projection shortcut은 사용하지 않기에 Identity mapping만 사용. 다운샘플을 통해 차원을 맞춰주며, 층마다의 첫 구조에서는 stride = 2를 사용해 크기를 2배로 맞춰준다.
class ResNet(nn.Module):
def __init__(self, in_channels, out_channels, nker=64, norm="bnorm", nblk=[3,4,6,3]):
super(ResNet, self).__init__()
self.enc = ConvBlock(in_channels, nker, kernel_size=7, stride=2, padding=1, bias=True, norm=None, relu=True)
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2_x = nn.Sequential(
ResBlock(64, 64),
ResBlock(64, 64),
ResBlock(64, 64)
)
self.conv3_x = nn.Sequential(
ResBlock(64, 128, short_cut = True, init_block = True),
ResBlock(128, 128),
ResBlock(128, 128),
ResBlock(128, 128)
)
self.conv4_x = nn.Sequential(
ResBlock(128, 256, short_cut = True, init_block = True),
ResBlock(256, 256),
ResBlock(256, 256),
ResBlock(256, 256),
ResBlock(256, 256),
ResBlock(256, 256)
)
self.conv5_x = nn.Sequential(
ResBlock(256, 512, short_cut = True, init_block = True),
ResBlock(512, 512),
ResBlock(512, 512),
)
self.averagepool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(nker*2*2*2, 10)
def forward(self, x):
x = self.enc(x)
x = self.max_pool(x)
x = self.conv2_x(x)
x = self.conv3_x(x)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.averagepool(x)
x = torch.flatten(x,1)
out = self.fc(x)
return out위의 클래스들을 사용해 크기가 맞지 않는 첫 initial block에서는 stride = 2, short_cut = True를 사용해 크기를 맞춰주며 진행하고, 마지막에 FC layer를 통해 결과값을 뽑는다.
'네이버 부스트캠프 학습 정리 > 4주차' 카테고리의 다른 글
| 4주차 회고 (0) | 2023.04.02 |
|---|---|
| [CV basic] Object Detection (0) | 2023.04.02 |
| [CV basic] Semantic Segmentation (0) | 2023.04.01 |
| [CV basic] Data Efficient Learning (0) | 2023.03.31 |
| [CV basic] AlexNet/VGGNet (0) | 2023.03.30 |